How to build a system that doesn’t fail on top of systems that do
Treating upstream instability as the default to create a faster, more reliable path to care
Thoughts
·
4 min

This article was written by Mike Danello.
In software, we tend to aim for perfection or as close as possible to it (think high nines or 100% code coverage), but the ecosystem we’re working in can sometimes make that almost impossible.
At Grow Therapy, we work closely with insurance payers and clearinghouses (which aggregate access to insurance payers) to help clients find care covered by their insurance and understand what they'll owe. But payer APIs are unreliable, prone to outages, and enforce rate limits. Even when available, these APIs can deliver ambiguous or even conflicting information about benefits.
If we’re not careful in how we handle these limitations, it can create real friction for clients booking their first session, causing them to delay, or worse, give up on getting care. To fulfill our mission of efficiently connecting clients with care, we need to navigate this complexity to deliver a consistent experience. And because we guarantee payouts to providers (and never pass costs from denied claims to clients), this is critical to ensuring our business model is sustainable.
In this blog post, we’ll share how our Coverage and Payments team, a group of seven engineers, built our eligibility system with reliability in mind despite the flakiness of the underlying systems.
Building on quicksand
Payer APIs are difficult to work with. The first challenge is getting a reliable API response. Many payer systems have been around for decades and expose real-time interfaces over legacy infrastructure — including mainframes running COBOL — that were never designed for high-concurrency workloads.
As a result, their APIs are prone to outages, timeouts, and inconsistent or partial responses under load. In turn, these payers enforce strict (and often opaque) rate limits to protect their underlying systems. Bursty retry behavior can trigger rate limits, causing cascading failures or prolonged downtime for everyone.
Ironically, naively retrying harder makes the system less reliable, not more. Some carriers exhibit 10–20% error rates on eligibility requests, driven by a mix of validation failures, system instability, and rate limiting.
When we successfully receive a response, the next challenge is payer entity resolution — mapping ambiguous user-provided insurance information and limited benefits data to the exact payer identity required by downstream systems.
This process unfolds against a highly fragmented payer landscape. For example, Blue Cross Blue Shield is not a single entity but a federation of ~30+ independent payers, each with its own systems and routing requirements. When a client selects that value from a dropdown, we must determine which of those entities (if any) actually administers their plan.
Similarly, not all eligibility payers are billing payers, and figuring that out provides another level of complexity we need to resolve. Some payers outsource their mental health benefits to third-party insurance providers, so identifying the eligibility payer isn’t enough. We also need to determine the billing provider so we can avoid denied claims.
Critically, payers do not explicitly tell us which entity is responsible; instead, we have to infer it from partial and often inconsistent data in the eligibility response. False negatives will block eligible, in-network clients from accessing care. False positives will lead to misrouted claims and downstream claim denials and rejections.

The shift: first principle fault tolerance
Rather than assuming (or hoping) the systems we work with are reliable, we assume that unstable conditions are the norm and design our insurance verification system around this principle. Doing so requires us to build a highly configurable pipeline that absorbs upstream chaos and rapidly adapts to exceptions without expensive code changes, allowing us to present a stable, predictable experience to clients. Let’s take a closer look at the key components of the system that make this possible.
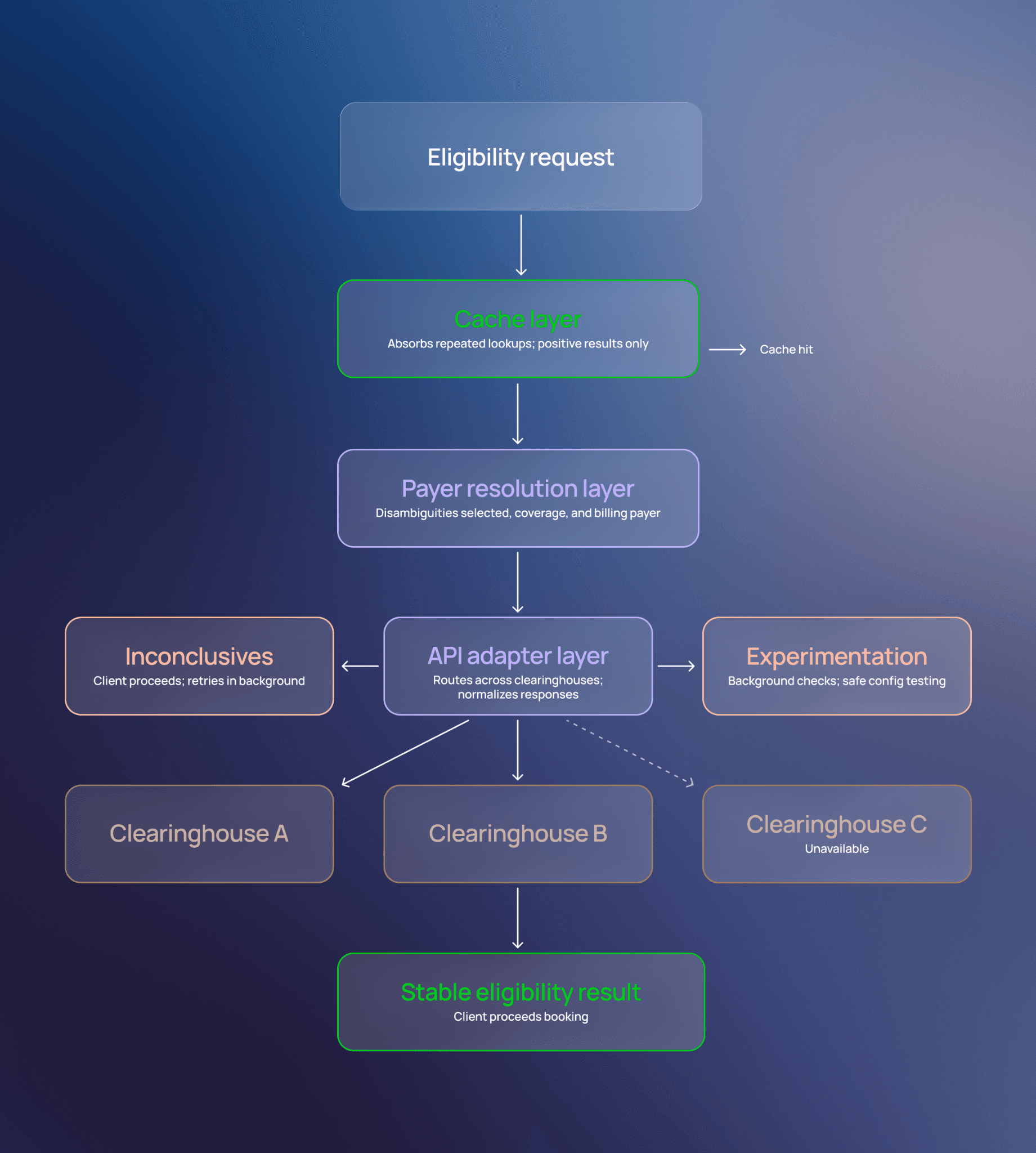
Cache for reliability, not speed
Caching is one of the simplest and most effective ways to smooth out insurance carrier API errors. Because policy data changes infrequently, it’s a prime candidate for caching.
We treat caching as a tool for correctness, not just performance — smoothing out the inconsistencies of real-time eligibility APIs rather than simply making them faster. This starts with being deliberate about what we cache: we cache positive eligibility results, but never ineligible ones. Clients can update their insurance details and self-service, and caching a stale “no” risks trapping them in an incorrect state.
Our cache strategy is also informed by the realities of insurance data. Most policies reset monthly, so we reset eligibility caches at the start of each month. At the same time, we recognize that not all data is equally stable — cost estimation fields, such as the remaining deductible, can change much more frequently, so we avoid long-lived caching for that data and instead refresh it daily.
Finally, we design for failure. When incorrect data is cached, we have tooling to perform targeted cache eviction at the client, payer, and clearinghouse levels, ensuring we can quickly restore correctness without broad disruption.
Inconclusives: a primitive for fault tolerance
When an insurance carrier fails to return a definitive answer due to an outage, a timeout, or an ambiguous response, we don’t block clients from receiving care. Instead, we classify the result as inconclusive, meaning clients can proceed with the booking while we continue to reach out to the payer API before their first appointment. By making this choice, we are prioritizing the client’s decision to seek care and preserve their momentum as they move from deciding to get help to actually getting help.
We treat the inconclusive as a first-class primitive, meaning it applies to all appointments. Each inconclusive trigger results in automatic background retries until a terminal result is reached (i.e., a definitive answer on whether their plan is active or inactive). This approach ensures clients can move forward with receiving care while the system continues working toward certainty behind the scenes.
This system allows us to preserve their momentum without sacrificing accuracy, which is especially important when payers send us bad or poor data. For instance, we once had a payer start returning prior auth errors for all of their clients, impacting thousands of insurance coverage policies. Instead of needing to manually intervene, our system allowed us to mark all requests as inconclusive and valid. Clients can focus on accessing care, and we can do our best to connect them rather than block them.
A resolution layer helps accurately identify the payer
To make payer identification more accurate, we built a payer resolution layer that disambiguates three distinct elements:
Which insurance the client selected
Who covers the member
Which entity to bill and route through
Together, we call this process payer calculation.
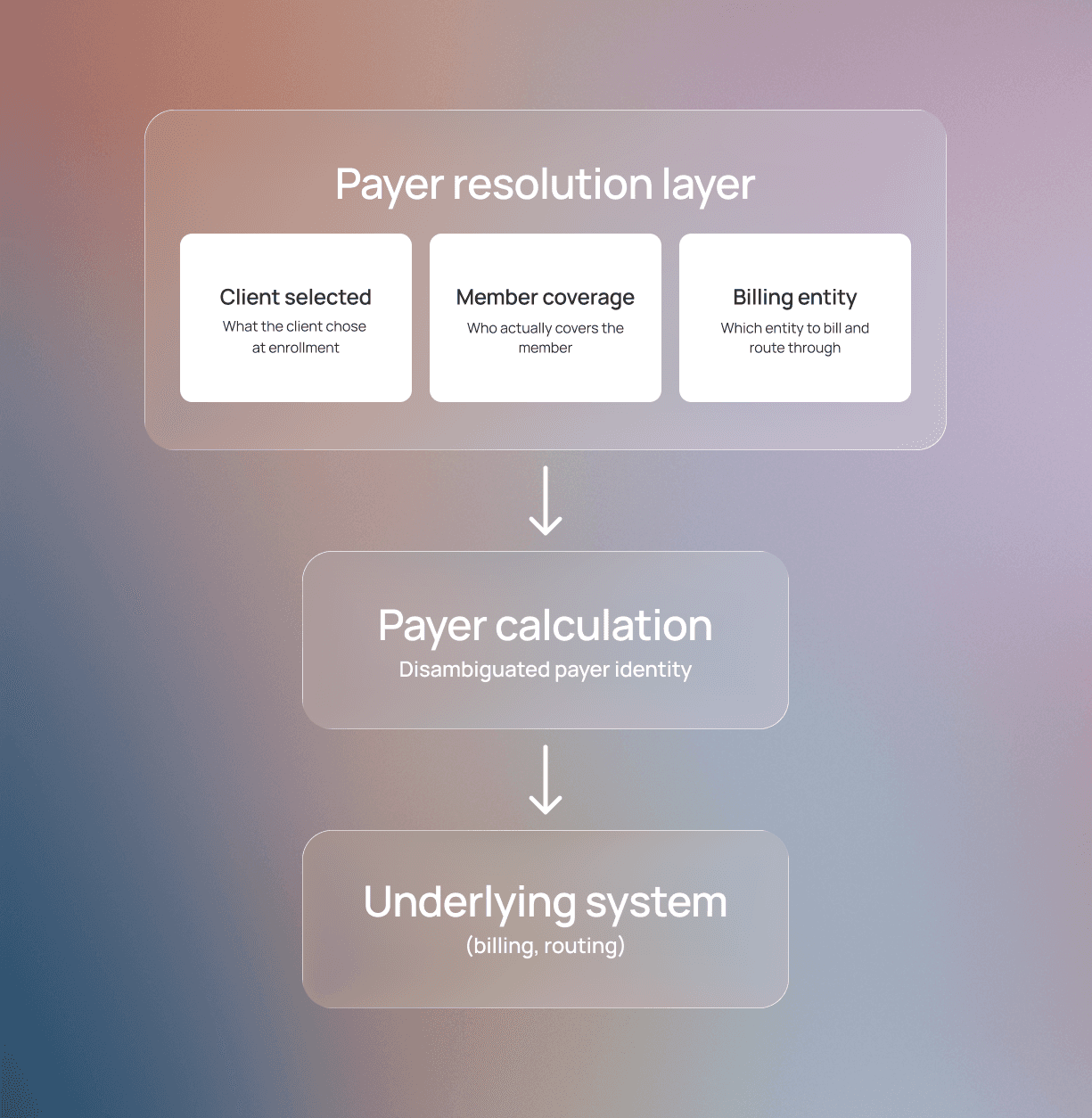
Payer calculation treats the client-selected payer as a starting signal, not ground truth. It routes an eligibility request, and the resulting response data drives payer resolution.
Routing is powered by a flexible rules engine designed for rapid iteration and safe experimentation. The rules engine operates on rich payer metadata, including group names, policy names, and benefit notes, and supports a wide range of matching strategies. Claims outcomes serve as the feedback loop, allowing our Revenue Cycle Management (RCM) team to iteratively improve routing accuracy.
Rules can be created in a provisional state and evaluated against historical data in real time, allowing teams to understand impact before activation — all without requiring a deploy. We currently maintain over 10,000 routing rules.
When the home payer (the entity that ultimately covers the member) differs from the servicing payer (the entity used for billing and routing), additional logic is required. Absorbing this complexity and producing a simple answer to upstream systems is the goal of payer calculation.
An API adapter layer protects against flakiness
Insurance clearinghouses are a critical dependency. In mid-2025, we moved to a multi-clearinghouse architecture to improve both resilience and data quality.
This approach delivers two key benefits.
First, data quality: different clearinghouses may return slightly different results for the same payer. Some clearinghouses route requests more intelligently or maintain stronger integrations with specific carriers, resulting in higher pass-through rates and richer eligibility data.
Second, resilience: while clearinghouse outages are relatively rare, they are highly consequential when they occur. By integrating with multiple clearinghouses, we ensure that failures in any one vendor don’t block eligibility checks.
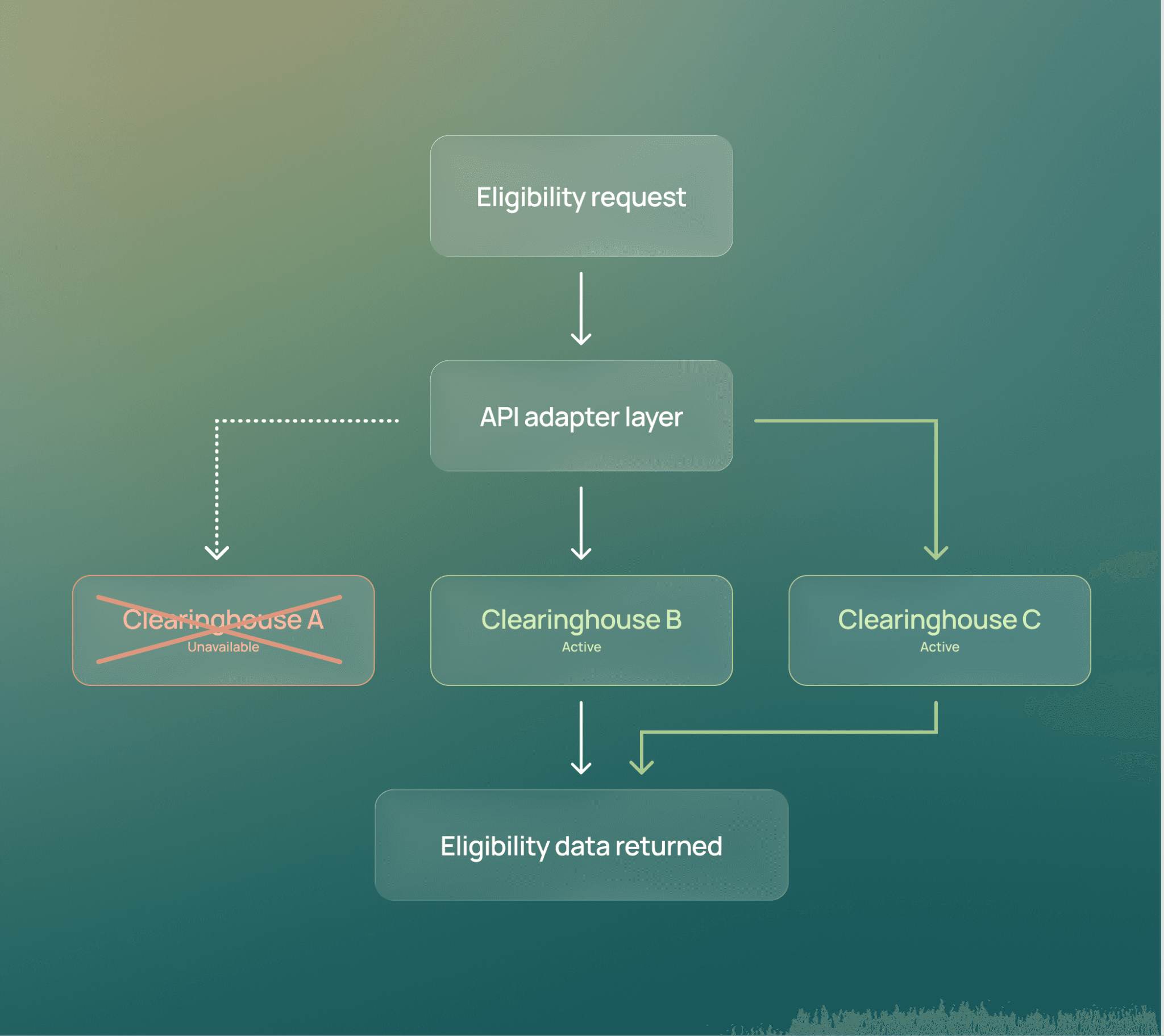
Clearinghouses, however, are not interchangeable. Each exposes different APIs, response formats, and behaviors. To abstract this complexity, we built an adapter layer that normalizes responses into a consistent format our upstream systems can rely on.
Now, if a clearinghouse goes down, we reroute eligibility checks to an alternative clearinghouse, based on whichever one is available and returns the best data.
This vendor-level redundancy ensures that even large-scale external failures don’t automatically turn into blocked verifications. Even better, this redundancy is runtime-configurable, so no code changes are needed if we need to shift routes on the fly.
Data-driven experimentation
Insurance data is inherently messy and highly variable, making production data the most reliable source for evaluating changes. Historical performance, however, is not a stable proxy for future outcomes. Given the high stakes — where incorrect routing or degraded eligibility results directly impact patient experience and revenue — we’ve built a set of paradigms that enable safe, large-scale experimentation in production.
First, we support batch checks, which allow us to run arbitrary eligibility requests at scale against historical or sampled datasets. This gives us a controlled way to evaluate new configurations, routing logic, or matching strategies.
Second, we run background benefit checks, which are non-blocking, duplicate eligibility requests, alongside live traffic. When a primary check is executed, we simultaneously issue a secondary check using the same inputs but a different configuration (e.g., service type codes, clearinghouse routing). These checks don’t affect the user experience but allow us to continuously test alternatives in real time.
We then use internal tooling to compare results side by side, evaluating metrics such as pass-through rate (e.g., more clients confirmed as eligible) and data quality. By capturing these apples-to-apples comparisons at scale, we can automatically detect when a new configuration performs better and promote it accordingly.
Together, these paradigms allow us to validate provisional routing rules and request construction changes safely, using real-world data, before rolling them out broadly.
Ensuring eligibility checks never stand in the way of care
We started working on this system in Grow’s early days, and the impact on clients receiving care has been meaningful across the board. As we've scaled to support significantly more users and payers, the system has stayed fast, reliable, and non-blocking throughout — allowing us to fulfill our mission to bring more seamless care to all.
False positives (clients we let in who don’t have in-network insurance or whose claims have been submitted to the wrong payer) have declined.
False negatives (eligible, in-network clients who get an eligibility failure and never book) are down.
The system has remained reliable and non-blocking even as we've grown significantly and added new payers.
Now, more than 26,000 providers have end-to-end support to deliver care on Grow, and today, 220M+ Americans have coverage through our 125+ health plans.
Reliability isn’t just about uptime, nor is it about ensuring just our part of the ecosystem is stable. True reliability requires removing barriers when someone is ready to seek care, and ensuring nothing as brittle as an insurance API stands in their way. At Grow, we don’t blame the constraints; we consider it our responsibility to work with them and around them.
If you're excited about tackling complex problems that directly affect clients, we'd love to hear from you. Check out our careers page for open roles.


